

【LabVIEW】1GBクラスの巨大なCSVファイル読込について

LabVIEWでの1GB以上あるCSVファイルを取り扱うための方法について紹介と解説を行っていきたいと思います。
32bitのLabVIEW環境では1GBのCSVファイルになってくると『区切られたスプレッドシート読み込み』では対応することが出来なくなってきます。
メモリが一杯というエラーが出てきます。
あと、CSVファイルの読み込みが非常に遅いという問題があります。
本記事では32bitのLabVIEW環境で非常に大きなCSVファイルを読み込んだ場合のメモリ不足解消とCSVファイル読み込み改善されたVIの紹介をします。
- 非常に大きなCSVファイルは標準の『区切られたスプレッドシート読込』を使用しない
- テキストファイル読み込み+スプレッドシート文字列を配列に変換を上手に活用する
- 生産者+消費者ループ、Foreループ並列で処理を高速化
- 数値の場合DBL(倍精度)の使用を控える
CSVファイル読み込むためのサンプルVI
How Can I Read a Very Large CSV File in LabVIEW?
(LabVIEWで非常に大きなCSVファイルを読み込むにはどのようにしたらよいでしょうか?)
https://knowledge.ni.com/KnowledgeArticleDetails?id=kA00Z0000015CQ0SAM&l=ja-JP
サンプルはLabVIEW2015のVIスニペットで配布されています。
使用するにはLabVIEW2015以降を使用してください。
VIスニペットを利用したい場合は、『名前を付けて画像を保存』を選択してください。
『画像をコピー』では元データではなく加工されたデータを取得してしまうため、VIスニペットとして機能しません。
巨大CSVを読み込むVIの解説
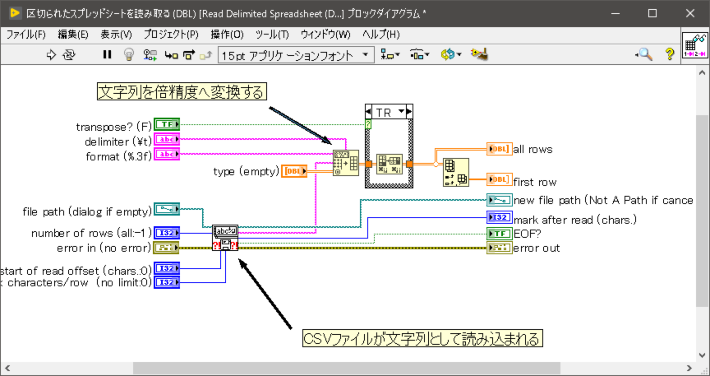
ブロックダイアグラム
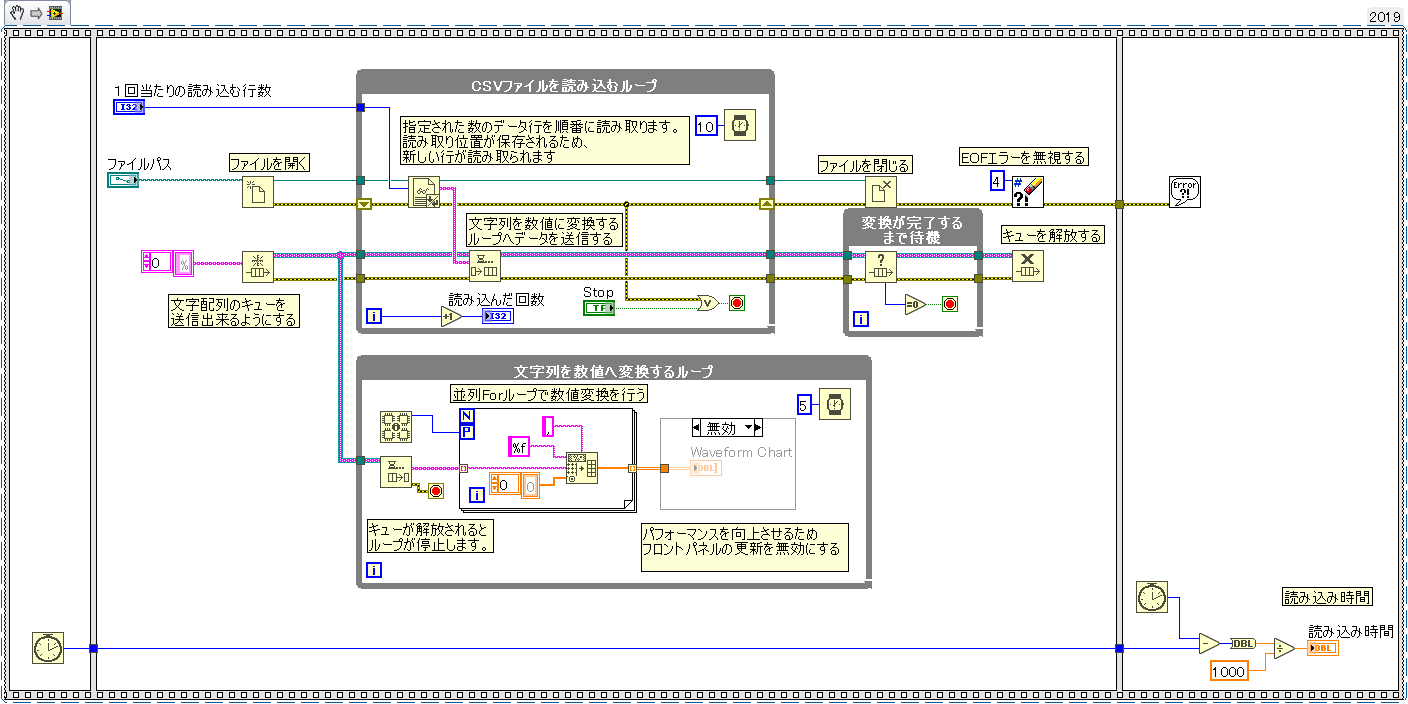
VI全体は上図のようになっています。
シーケンスストラクチャとティックカウントはプログラムの実行速度を計測するために使用されているので、CSVファイルの読み込みとは直接関係はありません。
フロントパネル
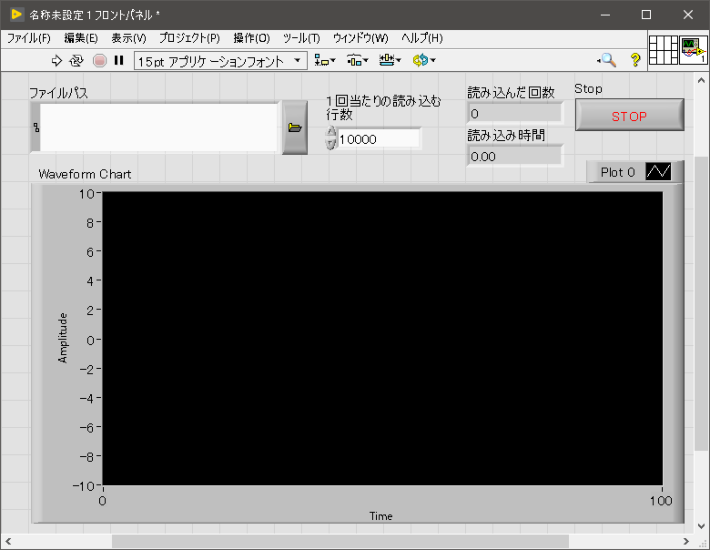
※Waveform Chartについては、ブロックダイアグラムでは無効にされているため、値が表示されない設定になっています。
理由としては非常に大きなCSVファイル値をフロントパネルに表示をさせる場合、読み込んだデータとは別にフロントパネルに表示をさせるためのデータがコピーされます。
値を表示するときは、表示をしないときの2倍メモリを多く使用することになります。
詳細については下記のVIメモリ使用のページにある『フロントパネルのメモリ問題』を参照ください。
https://zone.ni.com/reference/ja-XX/help/371361R-0112/lvconcepts/vi_memory_usage/
詳細解説
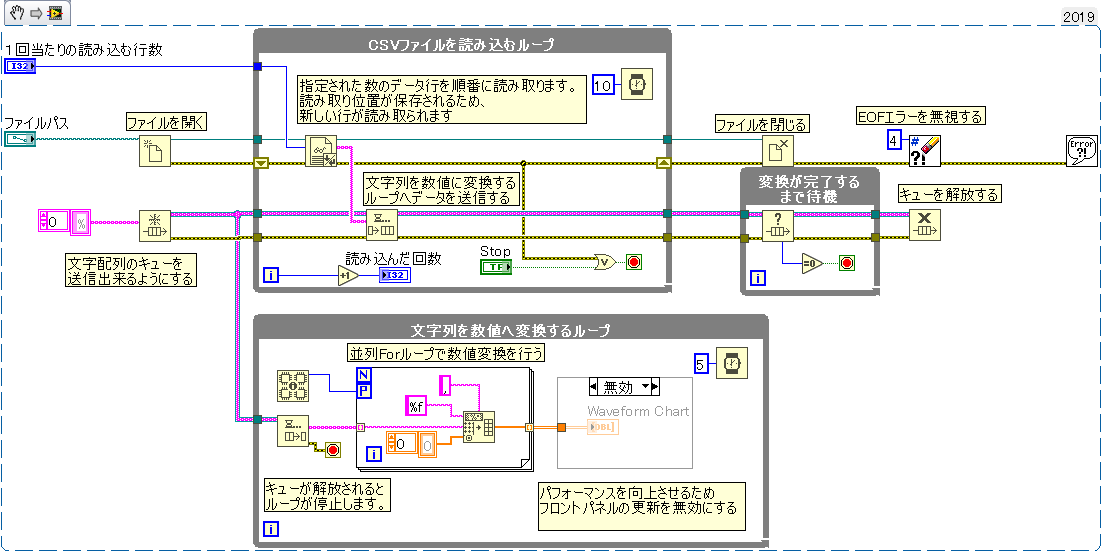
CSVファイルを読み込むのに必要な最小限の範囲
生産者、消費者の構成でプログラムが構築されています。
ファイルの読み込みと読み込んだデータの変換を別々に処理をすることによって処理速度を上げています。
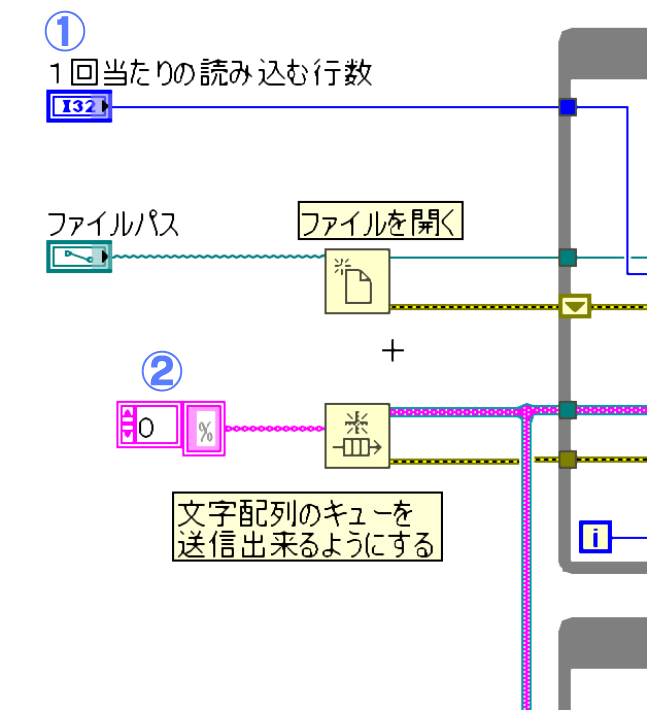
①
初期値として、CSVを読み込むためのファイルパスとCSVファイルを1回当たり読込行数を設定する必要があります。
読込行数が大きくなると、一時的に保持するデータが大きくなるので使用するメモリ使用量が増加するため注意が必要です。
②
テキストファイル(CSV)の読み込みを行単位で読み込むためキューの要素は文字列の配列に設定を行います。
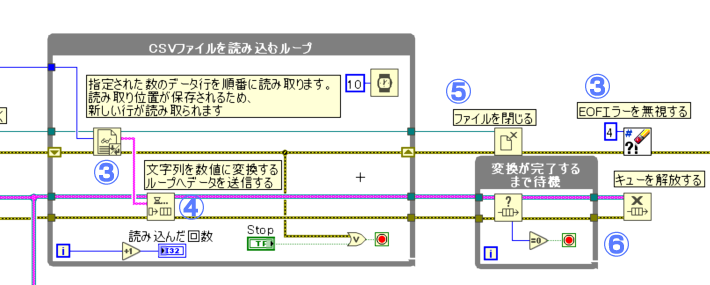
③
テキストファイルが標準だと文字列での読み込みになっているため、行単位(ライン読取り)に設定を変更します。
テキストファイルから読み取るを右クリックすると『ライン読取り』という項目があるので選択します。
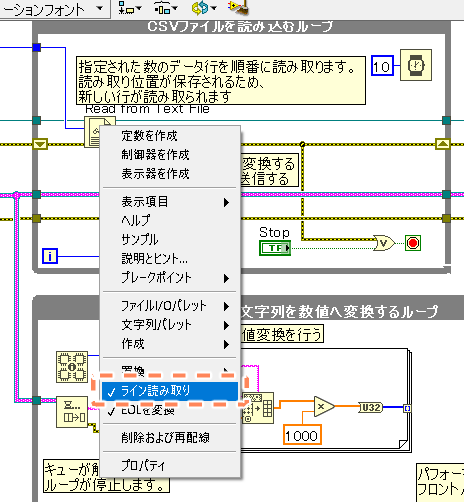
テキストの、読み込みですがストップボタンを押さない限りはファイルの最終行を超過して読み込みが行われます。
123456行のデータを1万行ずつ読み込むと13回目の読み込みで6544行足りません
そのため、必ずファイルの終端に遭遇したというEOFエラー(エラーNo4)が発生します。

また、エラーが発生した場合はファイルの中身を全て読み込んだか、正常に読み込めない状況になったと受け取れるのでループを停止させます。
EOFエラーについては既知(想定)のエラーなのでプログラムを全体停止する必要はありません。
しかし、エラーが発生している状態のままだと他のプログラムに影響するので、エラークリアでエラーを解消します。
EOFエラーを出さずに読み込む方法もありますが、読み込みが非常に遅くなります。
④
読み込んだ文字列の配列データをキューを使用して「文字列を数値データに変換するループ」へデータを送信します。
高速でCSVからデータを読み出したい場合は待機関数は不要です。
⑤
CSVファイルを読み込むループから、抜けた後は、開いていたファイルを閉じます。
閉じないと、LabVIEWを閉じるまでファイルを占有した状態になります。
⑥
キューについてはキュー内のデータが全て排出されているのかを確認した後、キューを解放します。
データがある状態でキューを解放するとデータも一緒に解放(削除)されます。
データの欠落を出さないようにするため、キューの排出が終わるまでキュー解放を待機しておく必要があります。
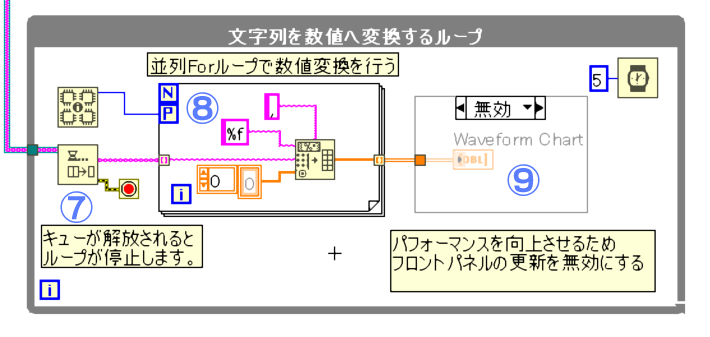
⑦
キュー送信されてきた文字列データを消費者ループ側で出力します。(要素をデキュー)
キューにデータが入力されるまでの間はキューから排出されるデータが無いのでデータが入力されるまで待機となります。
このループはキューの解放が行われたタイミングでキュー排出から、キュー解放に伴うエラーが出てきます。
エラーがあった場合、ループが停止するような仕組みになっています。
これも、想定されているエラーとなるためエラー処理は特にされていません。
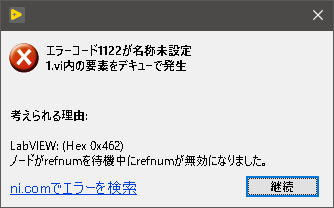
⑧
文字列のデータを『スプレッドシート文字列を配列に変換』という関数を用いて、文字列から数値配列データへと変換をします。
プログラムではカンマ区切りのCSVを前提としているため、デリミタが『カンマ』になっています。タブ区切りのCSVの場合は『タブ』に変更する必要があります。
文字列から数値への変換はデータに依存関係がないため、並列化したforループを使用することができます。
並列化をすることで変換処理を高速化することが出来ます。
⑨
WabeformChartについてはメモリの使用を抑えるために無効にされています。
CSVファイルを読み込むだけであれば、削除してしまっても問題ありません。
更に使用メモリを削減してみる
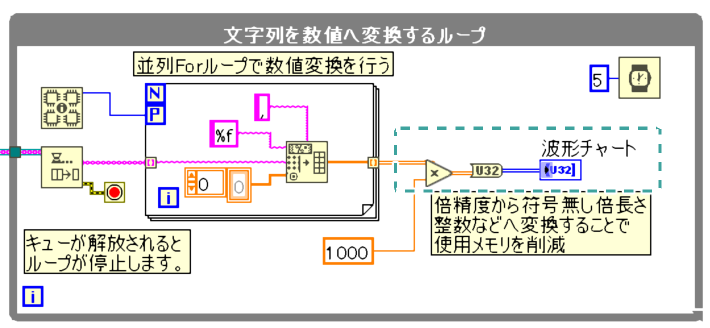
数値の型が倍精度だと、分割してCSVファイルを読み込んだとしても、配列データになった段階でメモリの使用量が大きくなります。
倍精度から符号無しの倍長さ整数等、倍精度よりも使用メモリの少ない型へ変換を行った方がメモリ使用量が減るためデータ処理が楽になります。
小数点の値が必要な場合は、一時的に必要な桁数分の値を乗算することで、小数点の値を保持することが出来ます。
データ処理後に、ファイルとして出力をする場合は、除算処理を入れることで、小数点の値を出力が出来ます。
グラフの表示値を元のデータ値で表示する
乗算した状態の値でどうしてもフロントパネルへ波形データなどを表示する必要がある場合は、フロントパネルのグラフ設定を変更することで元のデータ値で表示することが可能です。
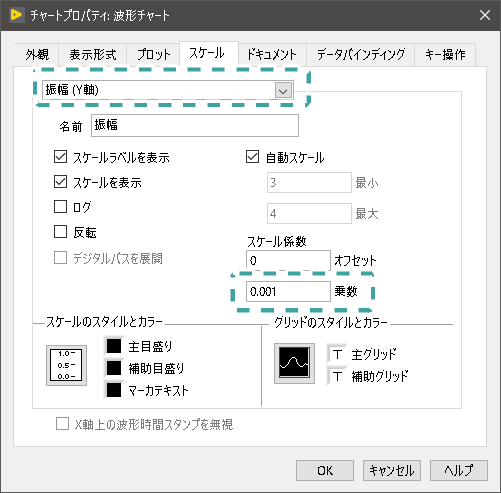
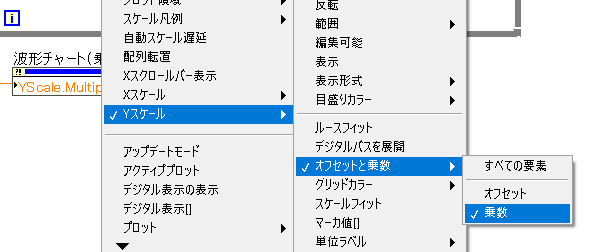
グラフのプロパティからスケールタブを選択します。
スケールタブの中にY軸を選択し『スケール係数』⇒『乗数』とあるので、値を乗算した値の逆数を記入すれば、元のデータ値でグラフが表示されます。
プログラムでグラフの乗数を変更したい場合は下記のように行います。
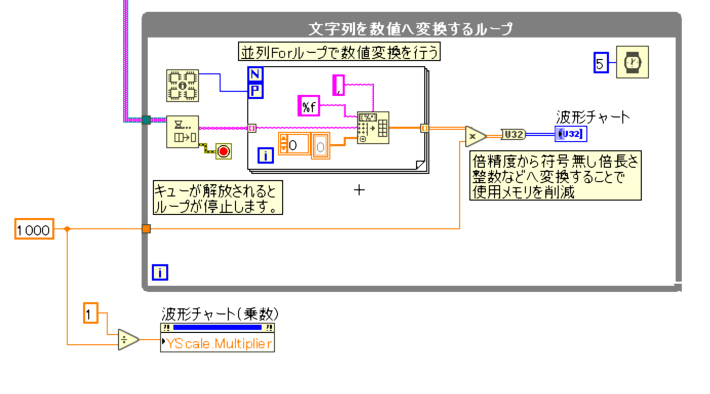
「Yスケール」⇒「オフセットと乗数」⇒「乗数」からグラフの乗数を変更するためのプロパティノードを読み出せます。
区切られたスプレッドシートを使用しない理由
CSVファイルを特に何も考えずにLabVIEWで読み込む場合、『区切られたスプレッドシート読込』を使用することが多いと思います。
しかし、非常に大きなCSVを読み込む場合、区切られたスプレッドシートでは読み込むことが出来ません。
メモリが一杯というエラーが発生します。
区切られたスプレッドシート読込でCSVファイルを読み込んだ場合、CSVファイル全体を一度で読み込もうとします。
仮に1GBのCSVファイルを読み込んだ場合、、LabVIEWは2GBのメモリを確保しようとします。(元データとコピーデータを保持するため)
32bitのLabVIEWは標準で使用できるメモリが2GBまでとなっており、1GBのCSVを読み込むと、メモリの上限に達してしまうため『メモリが一杯』というエラーが出ます。(設定を変更することで3GBまでは変更可能)
また、数値データで読み込む場合、『区切られたスプレッドシート読込』は内部で文字列を読み込んだ後に数値データに変換するという動作をしているため、読込と変換を同時に処理が出来ないので時間がかかります。
区切られたスプレッドシート読込を倍精度で読み込んだ場合のブロックダイアグラム
区切られたスプレッドシート読込は簡単にCSVファイルを読み込めるため使い勝手の良い便利なVIですが、非常に大きなCSVファイルを読み込む場合は、読込速度とメモリ管理の面から不利なVIと考えます。
区切られたスプレッドシート読込を改造して読込メモリ改善
約1年前に区切られたスプレッドシート読込の中身を変更してメモリ使用量を削減することにまでは成功していたのですが、読込に時間がかかっていました。
1.6GBのCSVファイルを読み込む場合、10分くらいかかってます。
区切られたスプレッドシート読込にも任意の行数を読み込むための機能があります。
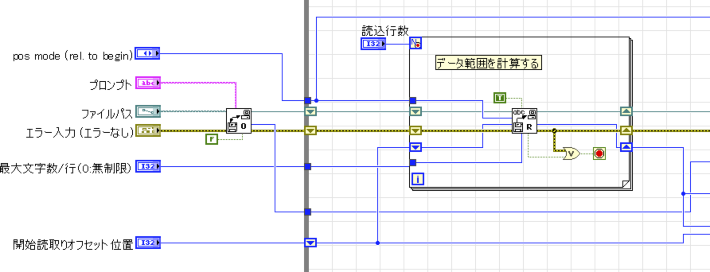
この時、読み込む行にあったデータの範囲を計算するのですが、データの範囲を計算するのに時間がかかっています。
内部で何度もCSVファイルにアクセスしていることが遅延している原因ではないかと考えています。
まとめ
- 32bit環境のLabVIEWで非常に大きなCSVファイルを扱う場合は、メモリの使用量に注意をしてください。
- データ容量が大きい場合は倍精度の使用を控えて、一時的に倍長整数を使用するのが望ましいです。あとで、必要なデータ範囲だけを倍精度に戻して出力すればOKです。
- 区切られたスプレッドシート読込は小さなCSVファイルの時は適していますが、大きなCSVファイルの読み込みには不向きです。
- 大きな数値データはLabVIEWで処理するよりも数値解析用のソフトであるMATLABやScilabにまかせた方が良さそうです。

同人イベント参加10回以上、クリスタ愛用者。 感覚的な説明では分からないことが多かったため、「理屈で考えて描く」を大切にしています。 自身の試行錯誤をもとに、イラストや同人活動の「なぜ?」を論理的に解決、効率的に、楽しく創作するヒントをお届けします。